

Table of Contents
Bag of word (BOW) or TF-IDF
The bag of words (BoW) model is a simple and widely used methodology for natural language processing (NLP) and text analysis. It displays the text in a way that takes into account word availability and ignores the order in which it appears. TF-IDF (Document Inverse Word Frequency), a statistical framework, was used to assess the importance of words in a document. It helps to reduce the burden of general terminology associated with a corpus and to focus on words that are more relevant to a particular document.
Both the Bag of Words (BoW) model or TF-IDF (Term Frequency-Inverse Document Frequency) function are used. Text-specific extractions but different purposes and characteristics.
Natural Language Processing (NLP) encompasses a variety of methods and techniques to enable computers to understand, interpret, and produce human language. Both Bag of Words (BoW) and TF-IDF (Term Frequency-Inverse Document Frequency) are foundational techniques in NLP that are text representation techniques for various projects
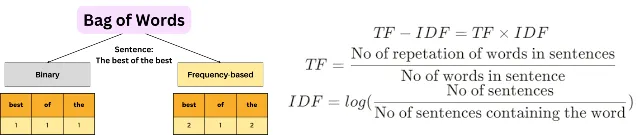
Some Point to Highlight for Bag of Word (BOW) or TF-IDF
- Weighting Scheme:
Bag of word (BOW) is used raw counts of words. Each word contributes equally to the vector based on its frequency in the document.
TF-IDF is Applies a weighting mechanism. Common words across many documents receive lower weights, while rare words that are significant to specific documents receive higher weights. - Feature Representation:
The resulting vectors can be sparse and high-dimensional, with many zeros for words not present in a particular document. Does not account for the importance of words, potentially leading to less informative features.
The vectors are also sparse, but the values reflect the importance of terms, making them more informative for tasks like text classification or clustering. - Handling Common Words:
BOW, Treats all words equally, so common words (like “the,” “is,” etc.) can dominate the representation.
TF-IDF is using different way, Reduces the influence of common words through the IDF component, allowing more meaningful terms to have a greater impact on the representation. - Use Cases:
Simple tasks where word order doesn’t matter, such as document classification or sentiment analysis, especially with a focus on overall word presence.
More suitable for tasks where the importance of terms is crucial, like search engines, document retrieval, and information filtering.
| Features | Bag of Word (BOW) | TF-IDF |
| Representation | Raw Word Counts | Weighted Counts |
| Importance of Words | Equal contribution | Based on Frequency and rarity |
| Handling Common Words | Dominated by common words | less impact from common words |
| Use cases | Basic text Classification | Search, Document retrival |
While BoW is a trustworthy method for text illustration, TF-IDF complements this method through incorporating the importance of phrases, making it extra effective for diverse NLP responsibilities.
Example of Bag of Word (BOW)
# Documents
text1 = “I love programming”
text2 = “Programming is fun”
text3 = “I love fun”
# create the vocabulary
unique words from all above documents [“I”, “love”, “Programming”, “is”, “fun”]
# create vectors
# convert each documents into a vector based on the vocabulary.
text1 = “I love programming”
vector = [1, 1, 1, 0, 0]
text2 = “Programming is fun”
vector = [0, 0, 1, 1, 1]
text3 = “I love fun”
vector = [1, 1, 0, 0, 1]
# Final Output is
text1 = [1, 1, 1, 0, 0]
text2 = [0, 0, 1, 1, 1]
text3 = [1, 1, 0, 0, 1]
This illustration lets in for truthful analysis and evaluation of files, even though it does not seize the semantics or order of words.
Example of TF-IDF
# Documents
text1 = “I love programming”
text2 = “Programming is fun”
text3 = “I love fun”
# Calculate the Term-Fequency
text1 = “I love programming”
TF(“I”) = 1/3
TF(“love”) = 1/3
TF(“programming”) = 1/3
text2 = “Programming is fun”
TF(“Programming”) = 1/3
TF(“is”) = 1/3
TF(“fun”) = 1/3
text3 = “I love fun”
TF(“I”) = 1/3
TF(“love”) = 1/3
TF(“fun”) = 1/3
# Calculate the Inverse Document Frequency
Total Documents = 3
“I” Apprears in 2 Documents -> IDF(“I”) = log(3/2)
“love” Apprears in 2 Documents -> IDF(“love”) = log(3/2)
“programming” Apprears in 2 Documents -> IDF(“programming”) = log(3/2)
“is” Apprears in 1 Documents -> IDF(“is”) = log(3/1)
“fun” Apprears in 2 Documents -> IDF(“fun”) = log(3/2)
# Calculate TF-IDF Scores
text1 = “I love programming”
TF-IDF(“I”) = (1/3)*log(3/2) => 0.059
TF-IDF(“love”) = (1/3) *log(3/2) => 0.059
TF-IDF(“programming”) = (1/3)*log(3/2) => 0.059
text2 = “Programming is fun”
TF-IDF(“Programming”) = (1/3)*log(3/2) => 0.059
TF-IDF(“is”) = (1/3)*log(3/1) => 0.366
TF-IDF(“fun”) = (1/3)*log(3/2) => 0.059
text3 = “I love fun”
TF-IDF(“I”) = (1/3)*log(3/2) => 0.059
TF-IDF(“love”) = (1/3)*log(3/2) => 0.059
TF-IDF(“fun”) = (1/3)*log(3/2) => 0.059
# Final Output
text1 = {“I”: 0.059, “love”: 0.059, “programming”: 0.059}
text2 = {“programming”: 0.059, “is”: 0.366, “fun”: 0.059}
text3 = {“I”: 0.059, “love”: 0.059, “fun”: 0.059}
TF-IDF scoring helps to identify which words in each document are most important to the corpus, making it useful for tasks such as document classification and information retrieval.
Conclusion
Choosing between BoW and TF-IDF relies upon on the unique necessities of your challenge. For packages that need a sincere illustration, BoW is a strong desire. However, for eventualities that require a deeper knowledge of word significance inside a corpus, TF-IDF provides a much better and insightful approach.